Introduction – Large Language Models
Today we’re interested in the Carbon Footprint Of Training GPT-3. By now most of the world knows about GPT-3 and its related cousin ChatGPT from OpenAI, a for-profit research institute that created it and has made its implementations available to any user. GPT-3 and ChatGPT are two examples of a general class of software architecture known as “Large language models”.
Large language models are a type of natural language processing (NLP) that uses machine learning to generate text with a high degree of accuracy. They are trained on a massive amount of data and are used in many applications such as chatbots, machine translation, and text generation.
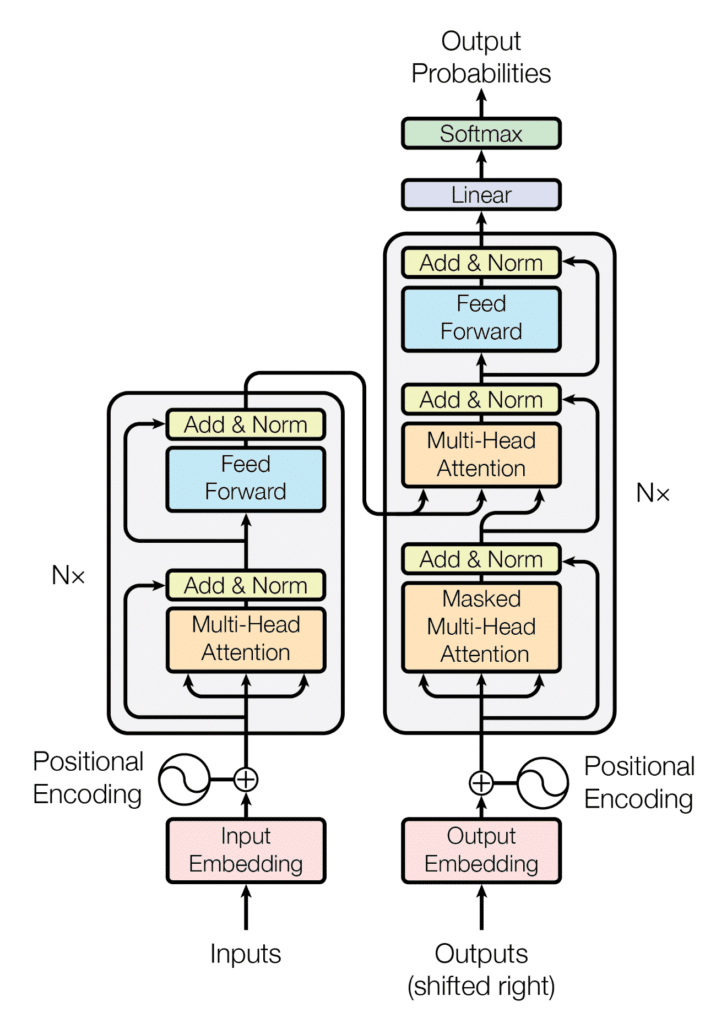
The training process involves feeding the model with text and then adjusting the weights of the model based on the results. The training process is computationally very expensive and is at the heart of reasons why we want to compute carbon footprint of training GPT-3.
LLMs Need To Be Trained Computationally
LLMs are built on transformer architectures which ingest massive amounts of text (e.g. Common Crawl, WebText2) and use a mechanism of encoding words as positionally aware embeddings to learn hidden high order correlation between words.
During training, the LLM is given a large corpus of text broken into “inputs” and “outputs”, where the inputs are simply a piece of text that precedes the output, a piece of text that succeeds the former. The LLM takes the inputs and masked pieces of the output, and trains using standard neural network backpropagation with the goal of optimizing for generating the outputs when given the inputs.
Training for GPT-3 means the semi-random adjustment of 175 billion parameters that must be “tuned” or “adjusted” so the output texts are what humans expect.
This is supposed to be done only once. But in reality, testing and development of the software, that “once” may happen over and over again. End users also have the option to “fine tune” the models which means more computation to adjust the parameters.
After many rounds of training, the result is a transformer neural network with billions of optimized parameter values that is able to not only “autocomplete” text, but to the degree where it writes entire paragraphs in a coherent way, respond in depth to questions, contextualizations, instructions.
GPT-3 is only the latest in a long line of language models and the field continues to explode in terms of novelty and frantic attempts to capitalize on the technology.
GPT-3 and ChatGPT are certainly the most popular but are not the largest. For example the Open Source BLOOM and proprietary PaLM from Google research are respectively 176 billion parameters and 500 billion parameters.
Training An LLM Is Carbon Intensive
First, the size of the data sets is massive. Common Crawl is one such training data set of text obtained by crawling the accessible internet. The Oct 2022 version contains 380 TiB (418 Terabytes) comprising 3.15 billion pages of the internet.
Second, the number of parameters in the billions is important because the more parameters there are, the longer it will take to train the model on the terabyte data sets, barring some unforeseen strange computational behavior.
Combined, it means that hundreds of thousands of hours of compute power are needed. This is why carbon footprint of training GPT-3 is such a hot topic. The compute takes place at large cloud data centers. These centers are distributed through the world.
As readers of this site know, the electric grid carbon intensity differs from place to place depending on its mix of energy sources. Solar, wind, hydro and nuclear power are ultra low in carbon intensity, whereas fossil fuels from natural gas to coal to oil are high carbon intensity.
Studies Have Examined And Proposed Ways To Quantify CO2 Impact
At least four studies have been released or presented on the carbon footprint of training LLMs. We will mention two of them here. Bannour et al 2021 reviewed 6 tools that purport to measure the CO2 impact of LLMs using a common framework of thinking. One of their cited tools is Lacoste et al 2019, which two years prior had published their software tool to compute the carbon impact of LLMs.
Estimating GPT-3 CO2 Footprint Due To Training
We used the Lacoste tool that is found here. We found a reference regarding the amount of compute needed to train GPT-3. Narayanan et al 2021 reported in the preprint.
Let us consider the GPT-3 model with 𝑃 =175 billion parameters as
Narayanan et al 2021 arXiv
an example. This model was trained on 𝑇 = 300 billion tokens. On
𝑛 = 1024 A100 GPUs using batch size 1536, we achieve 𝑋 = 140 teraFLOP/s per GPU. As a result, the time required to train this model
is 34 days.
Bearing in mind that carbon footprints are highly dependent on the local electrical grid, we will explore the footprint due to use of more than just one data center. First, there are two key numbers given above: n = 1024 over 34 days is equivalent to 835,584 hours of A100 GPU compute time. Second, we will need to estimate the CO2 footprint for different cloud providers over their different data centers.
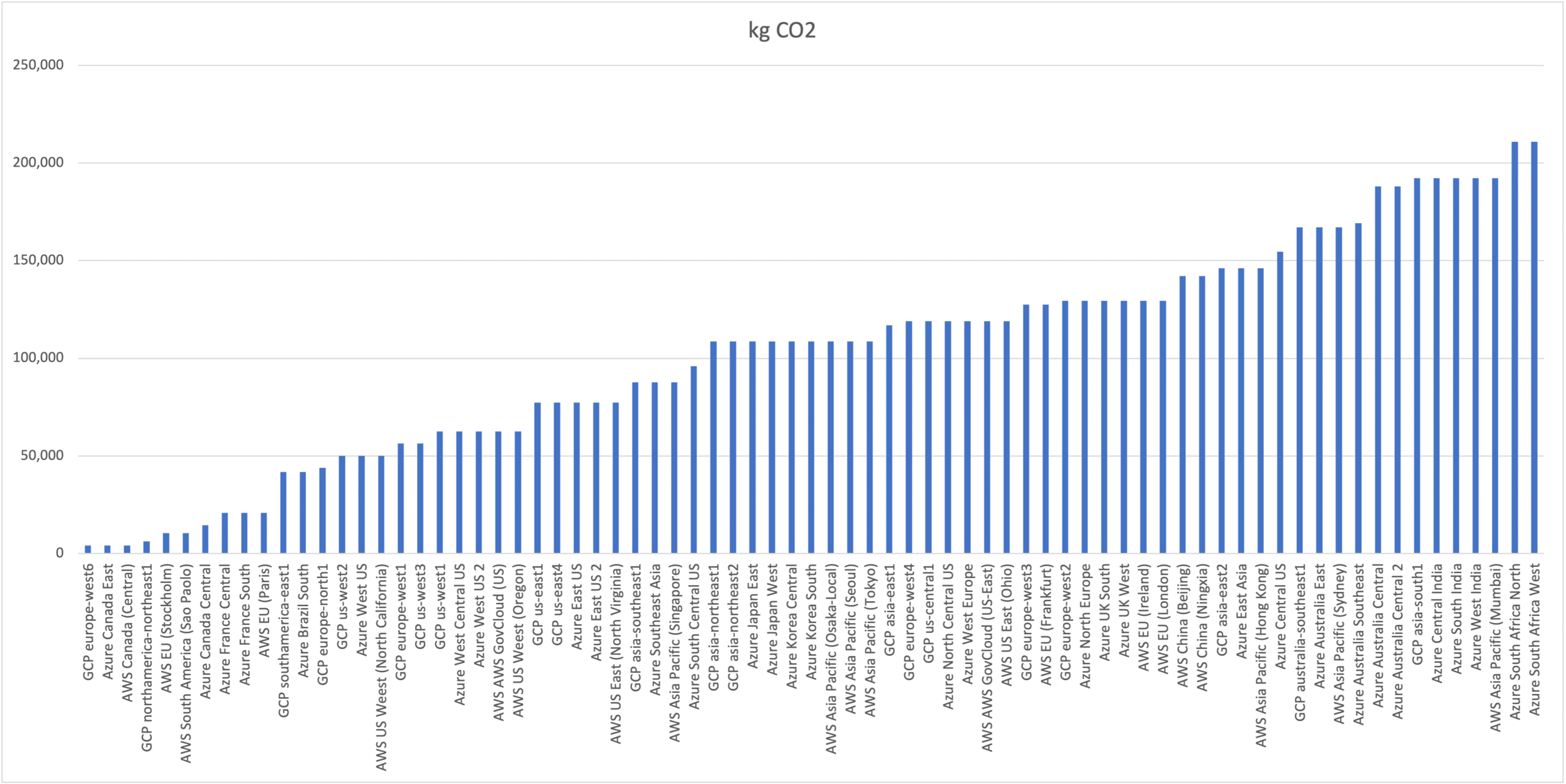
Results Show 50x Differences
The differences are astonishing. At the far left are the lowest carbon servers which expend about 4,000 kg CO2 for training the entire model. Two of the lowest three are in Canada in regions where hydroelectric power is dominant and one of them is in Switzerland which has a strong carbon neutrality initiative underway. At the far right, in the lowest three are two South African locations and one in India. Both countries are known to rely on carbon intensive electric grids with a high proportion of coal and oil sources.
As an aside, we’ve mentioned on this site, in some regions of the world where the grid is highly carbon intensive, the energy use is so low that these areas are not the problem in terms of carbon emissions for the world. The big emitters are the highly industrialized, high GDP countries with large populations like the US, China, parts of Europe.
We present the numbers from the chart in the table below.
Tabular Form Shows Numbers More Clearly
| Cloud | Region | Server-Region | kg CO2 (lowest to highest) |
| GCP | europe-west6 | GCP europe-west6 | 4,178 |
| Azure | Canada East | Azure Canada East | 4,178 |
| AWS | Canada (Central) | AWS Canada (Central) | 4,178 |
| GCP | northamerica-northeast1 | GCP northamerica-northeast1 | 6,267 |
| AWS | EU (Stockholm) | AWS EU (Stockholm) | 10,445 |
| AWS | South America (Sao Paolo) | AWS South America (Sao Paolo) | 10,445 |
| Azure | Canada Central | Azure Canada Central | 14,623 |
| Azure | France Central | Azure France Central | 20,890 |
| Azure | France South | Azure France South | 20,890 |
| AWS | EU (Paris) | AWS EU (Paris) | 20,890 |
| GCP | southamerica-east1 | GCP southamerica-east1 | 41,779 |
| Azure | Brazil South | Azure Brazil South | 41,779 |
| GCP | europe-north1 | GCP europe-north1 | 43,868 |
| GCP | us-west2 | GCP us-west2 | 50,135 |
| Azure | West US | Azure West US | 50,135 |
| AWS | US Weest (North California) | AWS US Weest (North California) | 50,135 |
| GCP | europe-west1 | GCP europe-west1 | 56,402 |
| GCP | us-west3 | GCP us-west3 | 56,402 |
| GCP | us-west1 | GCP us-west1 | 62,669 |
| Azure | West Central US | Azure West Central US | 62,669 |
| Azure | West US 2 | Azure West US 2 | 62,669 |
| AWS | AWS GovCloud (US) | AWS AWS GovCloud (US) | 62,669 |
| AWS | US Weest (Oregon) | AWS US Weest (Oregon) | 62,669 |
| GCP | us-east1 | GCP us-east1 | 77,292 |
| GCP | us-east4 | GCP us-east4 | 77,292 |
| Azure | East US | Azure East US | 77,292 |
| Azure | East US 2 | Azure East US 2 | 77,292 |
| AWS | US East (North Virginia) | AWS US East (North Virginia) | 77,292 |
| GCP | asia-southeast1 | GCP asia-southeast1 | 87,736 |
| Azure | Southeast Asia | Azure Southeast Asia | 87,736 |
| AWS | Asia Pacific (Singapore) | AWS Asia Pacific (Singapore) | 87,736 |
| Azure | South Central US | Azure South Central US | 96,092 |
| GCP | asia-northeast1 | GCP asia-northeast1 | 108,626 |
| GCP | asia-northeast2 | GCP asia-northeast2 | 108,626 |
| Azure | Japan East | Azure Japan East | 108,626 |
| Azure | Japan West | Azure Japan West | 108,626 |
| Azure | Korea Central | Azure Korea Central | 108,626 |
| Azure | Korea South | Azure Korea South | 108,626 |
| AWS | Asia Pacific (Osaka-Local) | AWS Asia Pacific (Osaka-Local) | 108,626 |
| AWS | Asia Pacific (Seoul) | AWS Asia Pacific (Seoul) | 108,626 |
| AWS | Asia Pacific (Tokyo) | AWS Asia Pacific (Tokyo) | 108,626 |
| GCP | asia-east1 | GCP asia-east1 | 116,982 |
| GCP | europe-west4 | GCP europe-west4 | 119,071 |
| GCP | us-central1 | GCP us-central1 | 119,071 |
| Azure | North Central US | Azure North Central US | 119,071 |
| Azure | West Europe | Azure West Europe | 119,071 |
| AWS | AWS GovCloud (US-East) | AWS AWS GovCloud (US-East) | 119,071 |
| AWS | US East (Ohio) | AWS US East (Ohio) | 119,071 |
| GCP | europe-west3 | GCP europe-west3 | 127,427 |
| AWS | EU (Frankfurt) | AWS EU (Frankfurt) | 127,427 |
| GCP | europe-west2 | GCP europe-west2 | 129,516 |
| Azure | North Europe | Azure North Europe | 129,516 |
| Azure | UK South | Azure UK South | 129,516 |
| Azure | UK West | Azure UK West | 129,516 |
| AWS | EU (Ireland) | AWS EU (Ireland) | 129,516 |
| AWS | EU (London) | AWS EU (London) | 129,516 |
| AWS | China (Beijing) | AWS China (Beijing) | 142,049 |
| AWS | China (Ningxia) | AWS China (Ningxia) | 142,049 |
| GCP | asia-east2 | GCP asia-east2 | 146,227 |
| Azure | East Asia | Azure East Asia | 146,227 |
| AWS | Asia Pacific (Hong Kong) | AWS Asia Pacific (Hong Kong) | 146,227 |
| Azure | Central US | Azure Central US | 154,583 |
| GCP | australia-southeast1 | GCP australia-southeast1 | 167,117 |
| Azure | Australia East | Azure Australia East | 167,117 |
| AWS | Asia Pacific (Sydney) | AWS Asia Pacific (Sydney) | 167,117 |
| Azure | Australia Southeast | Azure Australia Southeast | 169,206 |
| Azure | Australia Central | Azure Australia Central | 188,006 |
| Azure | Australia Central 2 | Azure Australia Central 2 | 188,006 |
| GCP | asia-south1 | GCP asia-south1 | 192,184 |
| Azure | Central India | Azure Central India | 192,184 |
| Azure | South India | Azure South India | 192,184 |
| Azure | West India | Azure West India | 192,184 |
| AWS | Asia Pacific (Mumbai) | AWS Asia Pacific (Mumbai) | 192,184 |
| Azure | South Africa North | Azure South Africa North | 210,985 |
| Azure | South Africa West | Azure South Africa West | 210,985 |
Perspective
Ok, now that we know GPT-3/LLMs are very carbon intensive to train and set up, lets put it into the right context. The average American emits about 15 tons of CO2 per year. The average person emits about 4-5 tons of CO2 per year. The most carbon intensive numbers for training GPT-3 hovers around 200,000 kg CO2, which translates to 200 tons of CO2 or 13 American’s emissions for one year or 50 (non-American) people’s emissions for one year.
The least carbon intensive numbers are around 4,000 kg CO2. Therefore, training GPT-3 with a clean grid is only 25% of an American’s or one non-American person’s worth of emissions for one year.
A car emits 5 tons of CO2 per year’s worth of driving. Therefore, training GPT-3 once on a clean grid is equal to driving 1 car for one year, and training on a dirty grid is equal to driving 40 cars for one year.
Let’s summarize the comparison of various carbon emitters to GPT-3 once.
| Emitter | Equivalent number to training GPT-3 once |
| Plane Ride | 345 flights across the US |
| Car | 40 cars driven for one year |
| Person | 13 American’s annual emissions or 50 non-American’s annual emissions |
Now, there are billions of people on the planet. Each person emitting 4 tons of CO2 per year is what causes the entire planet to generate gigatons of emissions.
How many GPT-3 models would we have to train to get to the gigaton range? The answer is 5,000,000 times. Let’s estimate whether we are anywhere near that number. There might be 100 large language models out there including BERT, GPT-2, PaLM, BLOOM etc, and let’s say each one was trained 100 times to get to where it is today. That would be 10,000 training sessions, or 2 million tons of CO2 emitted. That’s 1,000 times less than the gigaton range.
Basically, the LLM’s contribution of carbon emissions at the moment is a thousand times less than the other big three contributors of food, transportation, and heating and cooling.
Things may change however. Let’s say language models get bigger, into the trillion parameter range and the efficiency of training doesn’t change. Then perhaps we will see our world slowly ramp up the total LLM carbon emission cost.
LLMs Are Really Good At Modeling Language
One question readers may have is what use are these LLMs that warrant such expensive calculations? LLMs are already deployed for assistance with programming. Github Co-pilot works with programmers to generate code in an automated way. An open source version GPT-Code-Clippy carries out the same task. Besides programming, LLMs are so generally useful that they can do the following:
1. Machine Translation: Large language models can be used to accurately translate text from one language to another.
2. Speech Recognition: Large language models can be used to accurately recognize and transcribe speech.
3. Chatbots: Large language models can be used to develop more sophisticated chatbots that are capable of understanding natural language and carrying out conversations with humans.
4. Text Generation: Large language models can be used to generate coherent text that matches the style and content of the original source text.
5. Question Answering: Large language models can be used to answer questions based on a given context.
6. Image Captioning: Large language models can be used to generate captions for images.
Conclusions – Carbon Footprint Of Training GPT-3
We’re not saying that the carbon footprint of training GPT-3 doesn’t matter. Rather, many things matter, and if we had to prioritize what matters, it makes most sense to start with reducing emissions of our heating and cooling, reducing emissions related to food, and reducing emissions related to transportation. Starting with LLMs would not be productive. LLM training indeed will have an effect on carbon emissions but for now, its disproportionately small compared to other factors that dominate carbon emission.